Data-Warehouse-Power-BI-Sales-Dashboard
Sales Data Warehouse & Power BI Dashboard
 |
 |
 |
 |
 |
 |
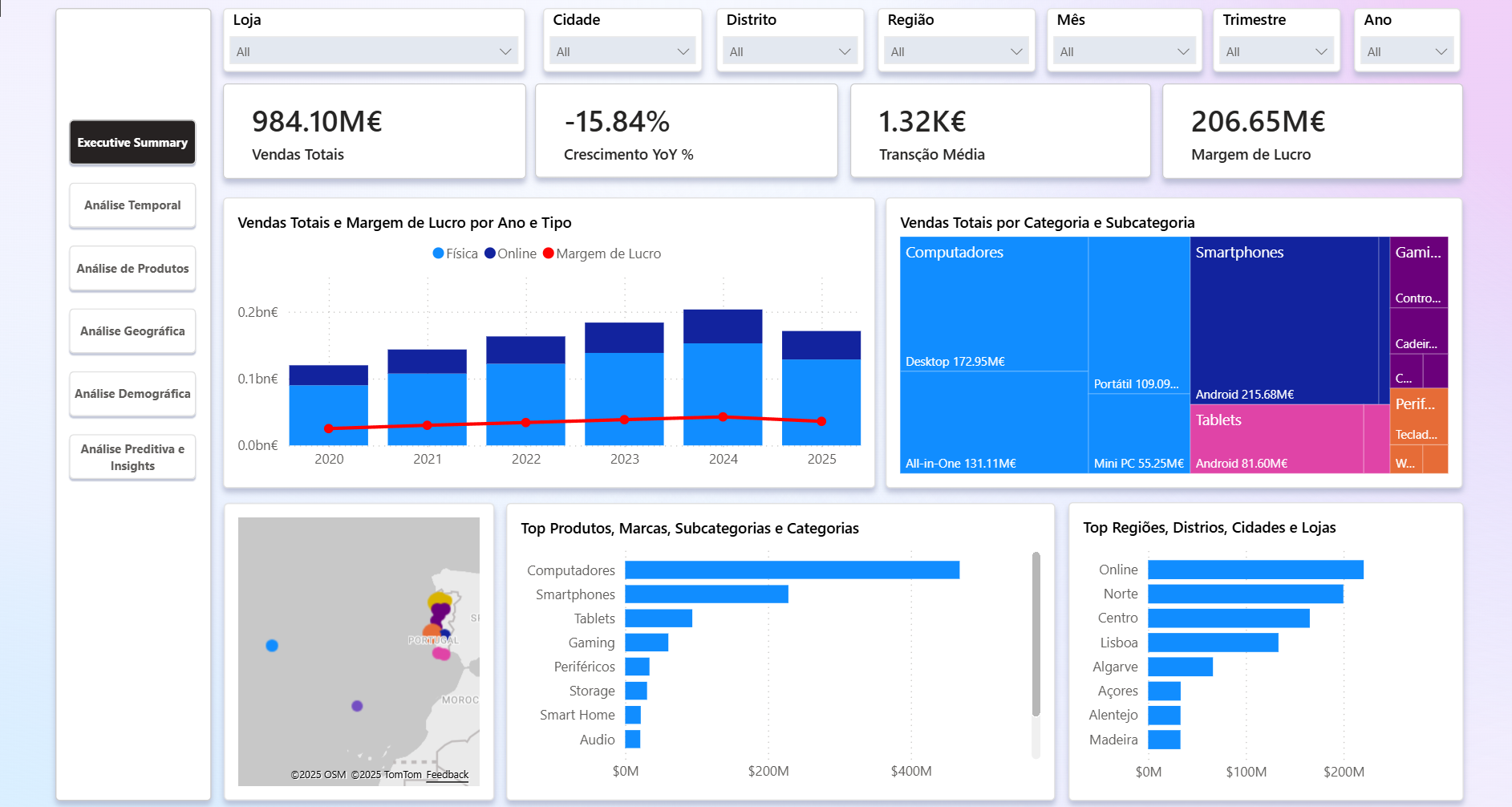
1. Resumo Executivo
Este repositório documenta, ponta a ponta, a construção de um mini data warehouse para a cadeia fictícia TechSolutions (retalho de eletrónica) e a entrega de dashboards em Power BI. Inclui geração de dados sintéticos (20 lojas, ~1,5k clientes, ~200 produtos, ~1,3M linhas de vendas 2020-2025), infraestrutura em Docker com SQL Server, pipeline ETL/ELT em Python + T-SQL, modelo dimensional em estrela e artefactos de Power BI (medidas DAX, cálculos visuais, scripts Python avançados e ficheiros .pbix).
2. Índice
- 3. Contexto de Negócio
- 4. Objetivos
- 5. Stakeholders e Perfis de Utilizador
- 6. Porque este DW importa
- 7. Arquitetura da Solução
- 8. Inventário de Fontes de Dados
- 9. Destaques de Modelação Dimensional
- 10. Estratégia de Snapshots e KPIs
- 11. Pipeline ETL / ELT
- 12. Layout do Repositório
- 13. Entregáveis Power BI
- 14. Primeiros Passos (Getting Started)
- 15. Validação e Testes
- 16. Operação e Manutenção
- 17. Roteiro (Roadmap)
- 18. Medidas DAX
- 19. Métodos Avançados em Python
- 20. Licença
3. Contexto de Negócio
- Retalho omnicanal de tecnologia em Portugal (lojas físicas + online).
- Necessidade de acompanhar crescimento, sazonalidade (Black Friday, Natal, Saldos) e rentabilidade por produto, loja e cliente.
- Painéis analíticos servem direção, equipas comerciais, marketing e operações.
4. Objetivos
- Consolidar dados transacionais de vendas num DW limpo e documentado.
- Disponibilizar modelo dimensional para BI self-service e relatórios corporativos.
- Expor KPIs chave (receita, margem, ticket médio, YoY/MoM, Pareto, cross-selling).
- Prover base para análises avançadas (clustering, PCA, forecasts Prophet).
5. Stakeholders e Perfis de Utilizador
- Direção / CFO: visão financeira (receita, margem, YoY, previsão).
- Direção Comercial: desempenho por categoria, produto, campanha e região.
- Operações de Loja: volume diário, stock inicial, picos/vales, staff planning.
- Marketing / CRM: retenção, frequência de compra, cross-sell, cohorts.
- Equipa de Dados/BI: manutenção do DW, qualidade e governo de dados.
6. Porque este DW importa
- Fonte única de verdade (SalesDW) com rastreabilidade desde CSV até dashboard.
- Modelo em estrela simplifica consumo em Power BI e garante performance.
- Estrutura preparada para growth (dados sintéticos >1M linhas, índices e schemas separados).
- Facilita reprodutibilidade (scripts versionados, Docker para infra local).
7. Arquitetura da Solução
- Geração de dados:
data/10804Proj3.pycria CSVs de lojas, clientes, produtos e vendas com sazonalidade e crescimento anual. - Orquestração: Docker Compose com dois serviços (
docker/docker-compose.yml):mssql: SQL Server 2022 com ferramentassqlcmd/bcp(Dockerfile.mssql).loader: container Python com ODBC, pandas e SQLAlchemy para ingestão (Dockerfile.loader).
- ETL/ELT: carga de CSV para
stagingviaetl/ingest_csv.py, transformação em T-SQL (sql/00_init_schema.sqla04_views.sql). - Camada de consumo: Power BI liga a
dw.FACT_VENDASe dimensões, usa medidas DAX e scripts Python para análises adicionais. - Artefactos: snapshots
.pbixdatados (Dashboard20251123.pbix).
8. Inventário de Fontes de Dados
data/lojas.csv: 21 lojas (online + físicas), com localização, região e tipo.data/clientes.csv: ~1,5k clientes com nome, email, telefone, género, loja de origem, idade, data_registo.data/produtos.csv: ~200 produtos com categoria, subcategoria, marca, preço de venda, custo, margem, stock_inicial.data/vendas.csv: ~1,3M linhas (2020-01-01 a 2025-10-31), comvenda_id,data_venda, chaves, quantidade, preço, desconto, custo, valor_total.- Auxiliares:
data/Cidade.csv,data/Distrito.csv(lookup geográfico),data/lojas.csv/produtos.csvgerados pelo script.
9. Destaques de Modelação Dimensional
- Esquema em estrela no schema
dw:DIM_DATA: surrogate keydata_id, atributos de calendário (ano, trimestre, mês, dia_semana), populada a partir de vendas e data_registo de clientes.DIM_LOJA: mantémloja_idnatural, linha “Desconhecido” para ligações faltantes.DIM_CLIENTE:cliente_idnatural, enriquece com loja, geografia e faixa etária; cobre clientes só presentes em vendas.DIM_PRODUTO:produto_idnatural, atributos de categoria, marca, margem, preço e custo.FACT_VENDAS: grão por linha de venda; FKs para todas as dimensões; métricasquantidade,preco_unitario,desconto_pct,custo_unitario,valor_total,stock_inicial;transacao_idviaDENSE_RANK(data+loja+cliente).
- Índices de apoio em staging (
data_venda,loja_id,cliente_id,produto_id) para acelerar lookups. - Views:
dw.vw_cliente_loja(cliente ↔ loja),vw_Vendas_Agregadas(ordens, recência, frequência, valor).
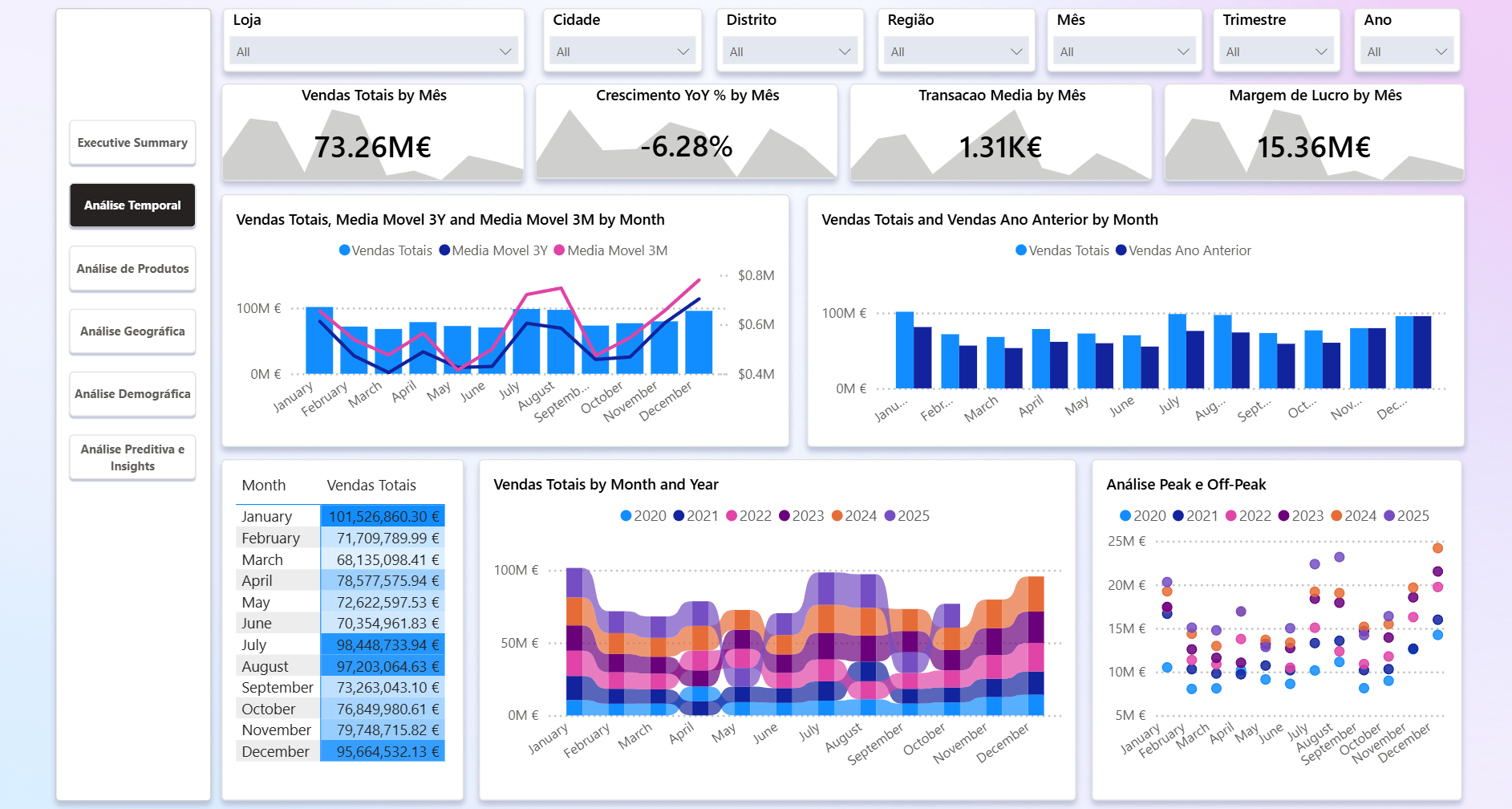
10. Estratégia de Snapshots e KPIs
- Grão diário para vendas;
DIM_DATAgarante cálculo consistente de YoY/MoM/QoQ/YTD. - KPI base: Vendas Totais, Quantidade, Nº Transações, Ticket Médio, Margem.
- KPI de crescimento: YoY, MoM, QoQ e médias móveis (3M/3Y).
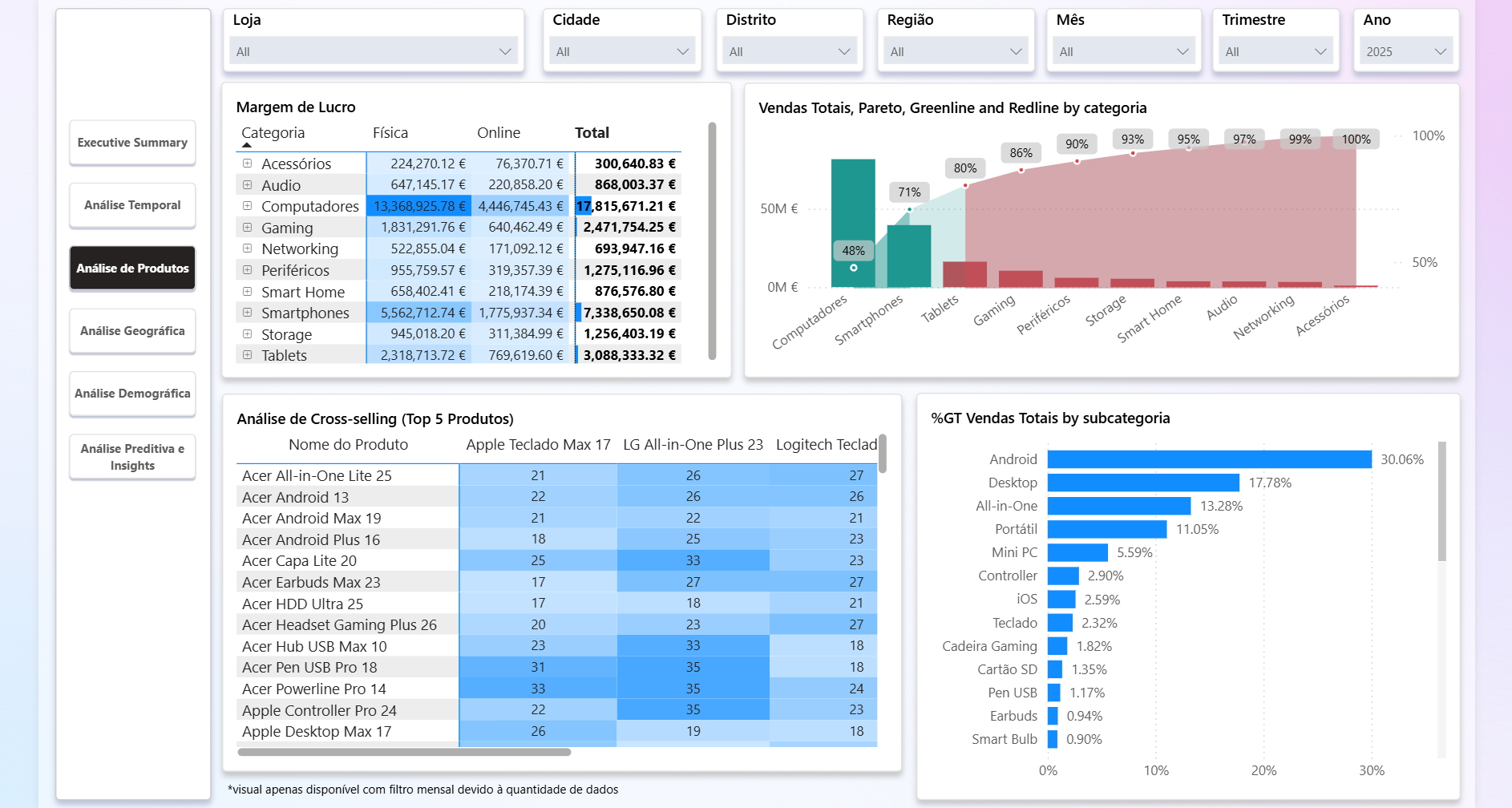
- KPI de distribuição: Pareto 80/20, ranking de produtos e contribuição percentual.
- KPI de operação: Peak vs Off-peak (mês acima/abaixo da média),
stock_inicialpara controlo de ruptura.
11. Pipeline ETL / ELT
1) Gerar dados: python data/10804Proj3.py (gera ou regenera CSVs com seeds fixos).
2) Subir infra: docker compose up -d --build a partir de docker/ (usa variáveis de docker/.env).
3) Ingestão para staging: no container loader, correr python etl/ingest_csv.py (cria BD se não existir, varre DATA_PATH, grava tabelas sanitizadas com nomes derivados do caminho).
4) Normalização staging: sql/01_staging.sql tipa colunas e cria índices.
5) Dimensões: sql/02_dimensions.sql cria DIM_DATA, DIM_LOJA, DIM_CLIENTE, DIM_PRODUTO, trata desconhecidos e faixas etárias.
6) Fato: sql/03_facts.sql popula dw.FACT_VENDAS, recalcula valor_total se nulo e associa stock_inicial.
7) Views: sql/04_views.sql expõe joins frequentes e métricas agregadas por cliente/transação.
12. Layout do Repositório
data/: script de geração (10804Proj3.py) e CSVs de origem.etl/:ingest_csv.pyerequirements.txtpara o loader.sql/: scripts de criação/carga (00_init_schema.sqla04_views.sql) equeries/queries.sqlpara smoke tests.docker/:docker-compose.yml, Dockerfiles e.envexemplo.powerbi/: medidas DAX, cálculos visuais, scripts Python (clusterização, PCA, Prophet) e tabelas auxiliares.img/: recursos de imagem (se aplicável)..gitattributes,.gitignore,LICENSE,README.md.
13. Entregáveis Power BI
- Ficheiros
.pbixdatados na raiz (último:Dashboard20251123.pbix). - Medidas DAX base e de time intelligence (
powerbi/DAX.md). - Cálculos visuais (Pareto, Cross Selling Matrix, Cohort) em
powerbi/Visual_calculations.md. - Query M para Cross Selling (
powerbi/Cross Selling.md) que gera pares de produtos por transação e conta vendas combinadas. - Tabelas auxiliares para slicers (ex.:
powerbi/tabelas_auxiliares.md). - Scripts Python para visuais avançados (clusterização, PCA, forecast). Usar num visual Python ou adaptar para ficheiro externo.
14. Primeiros Passos (Getting Started)
Pré-requisitos: Docker + Docker Compose, Python 3.11, ODBC Driver 17 para SQL Server (no host ou dentro do container loader), Power BI Desktop para abrir .pbix.
1) Clonar o repositório e posicionar-se na pasta sales-dashbaord/.
2) (Opcional) Regenerar dados: python data/10804Proj3.py.
3) Subir infra: cd docker && docker compose up -d --build.
4) Instalar dependências no loader: docker compose exec loader pip install -r etl/requirements.txt.
5) Correr ingestão: docker compose exec loader python etl/ingest_csv.py.
6) Executar scripts SQL na ordem 00→04 (via SSMS, Azure Data Studio ou sqlcmd):
docker compose exec mssql /opt/mssql-tools18/bin/sqlcmd -S localhost -U sa -P $MSSQL_PASSWORD -i /sql/00_init_schema.sql
# repetir para 01_staging.sql, 02_dimensions.sql, 03_facts.sql, 04_views.sql
7) Abrir o .pbix no Power BI Desktop, apontar a ligação para o servidor/BD locais (SalesDW) e atualizar as tabelas.
15. Validação e Testes
- Smoke tests SQL:
sql/queries/queries.sql(TOP 5 em cada tabela/view) para confirmar cargas. - Controlo de volumes: comparar contagens de staging vs fact (
COUNT(*),COUNT DISTINCTpor chaves), verificar datas mín/max. - Qualidade de dados: procurar nulos inesperados (lojas, produtos), verificar linha “Desconhecido” apenas para casos sem correspondência.
- Power BI: validar se relações estão ativas (1:*), se medidas retornam valores (Ticket Médio = Vendas Totais / Nº Transações).
- ETL: logs do
ingest_csv.pysinalizam ficheiros falhados; repetir após corrigir.
16. Operação e Manutenção
- Regenerar dados sintéticos quando quiser simular novos cenários (reescreve CSVs). Seeds fixos garantem reprodutibilidade.
- Recriar DW após alteração de schema: correr
01→03para reprovisionar staging/dimensões/fato. - Rever índices se o volume crescer; considerar partição de
FACT_VENDASpor data. - Backups: snapshots do container
mssql_dataouBACKUP DATABASE SalesDWviasqlcmd. - Power BI: versionar
.pbixpor data; limpar queries não usadas; atualizar credenciais ao mover ambientes.
17. Roteiro (Roadmap)
- CI/CD local: script ou pipeline que automatize compose → ingestão → SQL scripts → refresh PBI.
- Incremental refresh em Power BI para reduzir tempo de atualização.
- Testes de qualidade de dados automatizados (Great Expectations/SQL checks) e monitoria de frescura.
- Enriquecer modelo com fatos agregados diários, dimensão Campanha/Canal e preços promocionais.
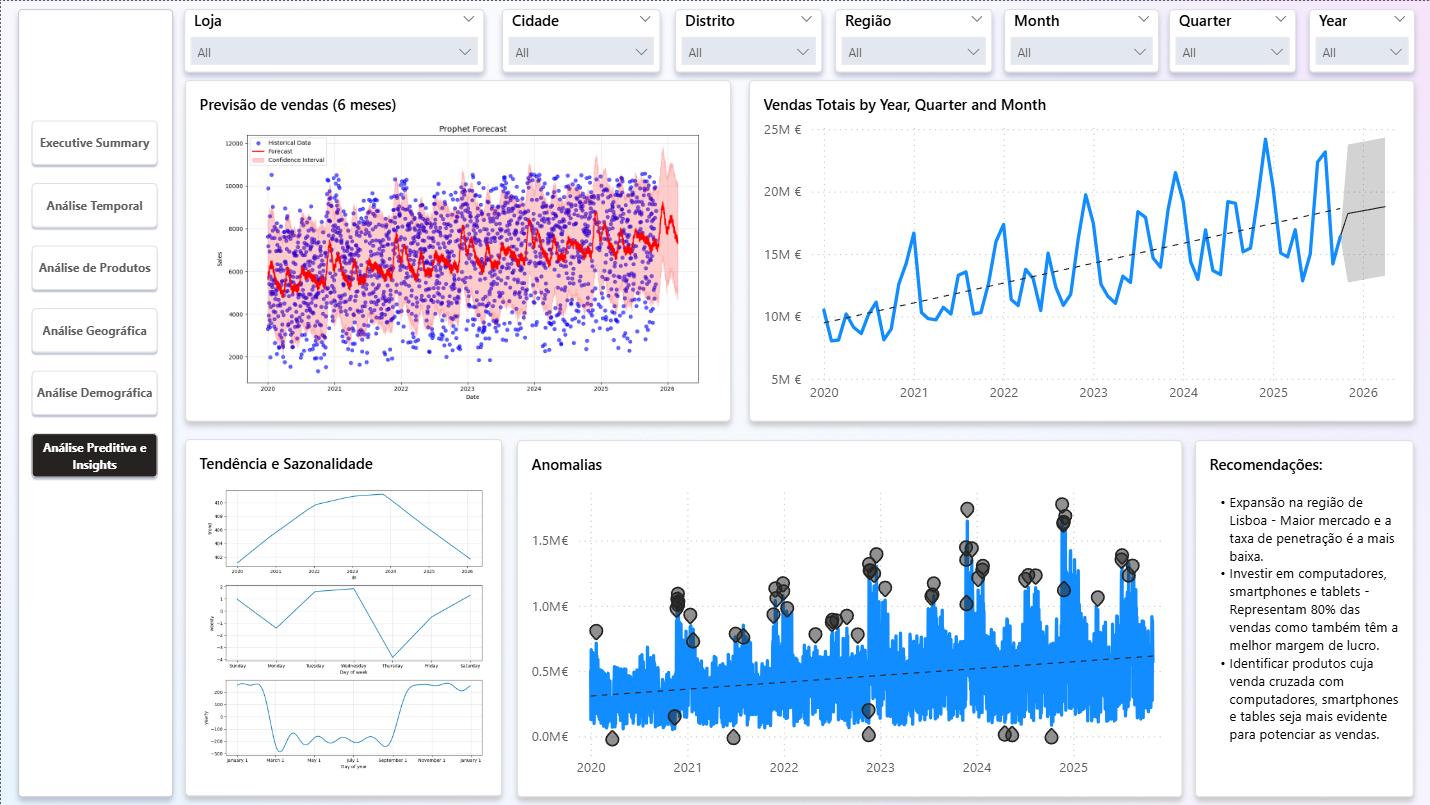
- Previsão avançada: comparar Prophet vs ARIMA e incorporar intervalo de confiança no dashboard.
18. Medidas DAX
Vendas Totais = SUM ( 'dw FACT_VENDAS'[valor_total] )
Quantidade Vendida = SUM ( 'dw FACT_VENDAS'[quantidade] )
Numero de Transacoes = DISTINCTCOUNT ( 'dw FACT_VENDAS'[transacao_id] )
Transacao Media = DIVIDE ( [Vendas Totais], [Numero de Transacoes] )
Margem de Lucro =
SUMX ( 'dw FACT_VENDAS', 'dw FACT_VENDAS'[quantidade] * ( 'dw FACT_VENDAS'[preco_unitario] - 'dw FACT_VENDAS'[custo_unitario] ) )
Crescimento YoY % =
VAR AnoSelecionado = CALCULATE( MAX('Calendario'[Ano]), ALLSELECTED('Calendario') )
VAR AnoAnterior = AnoSelecionado - 1
VAR VendasAtual = CALCULATE( [Vendas Totais], 'Calendario'[Ano] = AnoSelecionado )
VAR VendasAnterior = CALCULATE( [Vendas Totais], 'Calendario'[Ano] = AnoAnterior )
RETURN IF( NOT ISBLANK(VendasAtual) && NOT ISBLANK(VendasAnterior), DIVIDE(VendasAtual - VendasAnterior, VendasAnterior) )
Media Movel 3M =
VAR UltimaData = MAX ( 'dw DIM_DATA'[data] )
RETURN CALCULATE ( AVERAGEX ( DATESINPERIOD ( 'dw DIM_DATA'[data], UltimaData, -3, MONTH ), [Vendas Totais] ), REMOVEFILTERS ( 'dw DIM_DATA'[data] ) )
Media Movel 3Y =
VAR UltimaData = MAX ( 'dw DIM_DATA'[data] )
RETURN CALCULATE ( AVERAGEX ( DATESINPERIOD ( 'dw DIM_DATA'[data], UltimaData, -3, YEAR ), [Vendas Totais] ), REMOVEFILTERS ( 'dw DIM_DATA'[data] ) )
Vendas Ano Anterior = CALCULATE( [Vendas Totais], SAMEPERIODLASTYEAR(Calendario[Date]) )
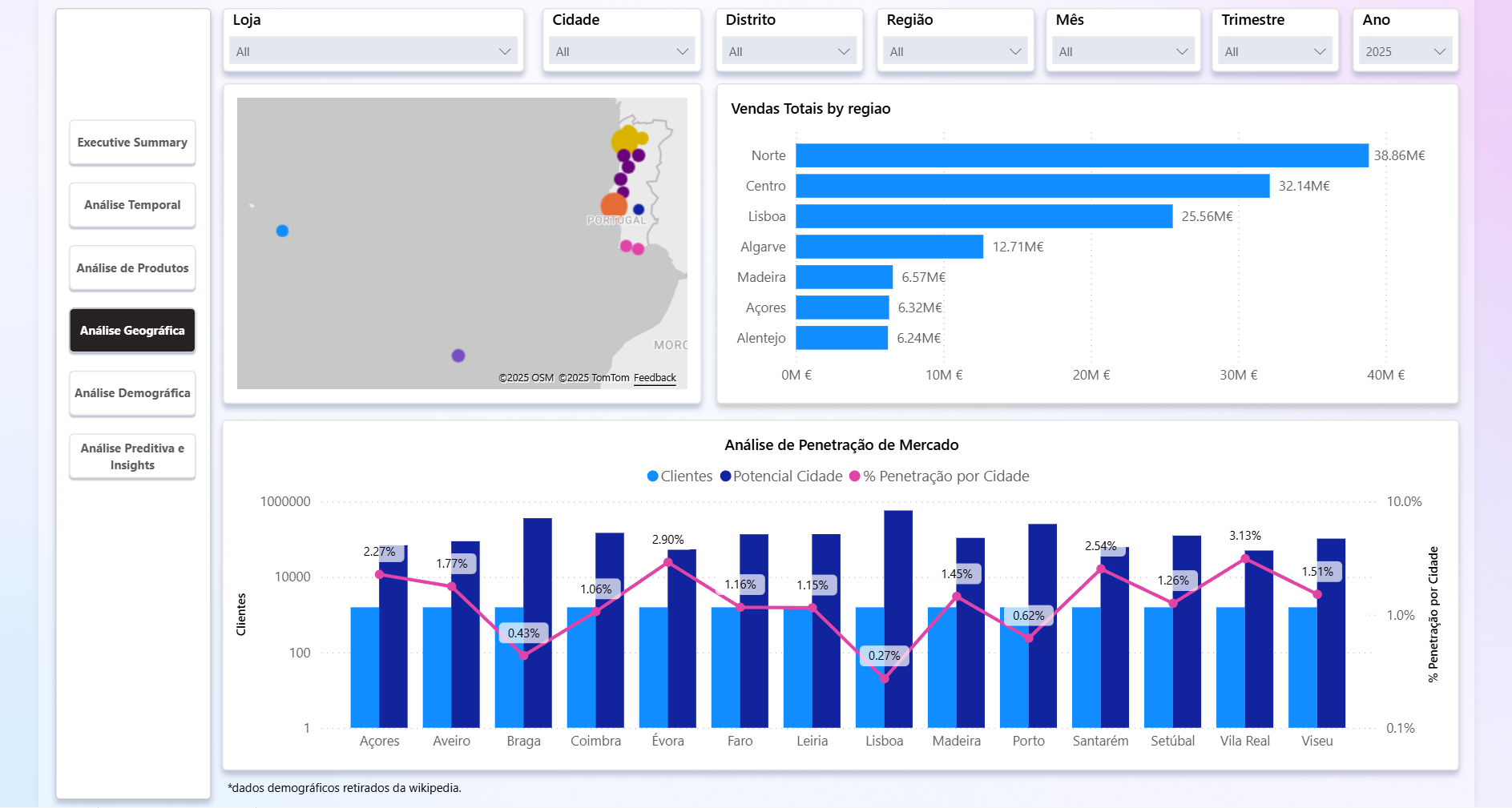
Clientes = DISTINCTCOUNT ( 'dw DIM_CLIENTE'[cliente_id] )
Potencial Cidade = CALCULATE( SUM( 'Cidade'[Habitantes] ), TREATAS( VALUES( 'dw DIM_LOJA'[cidade] ), 'Cidade'[cidade] ) )
% penetracao cidade = DIVIDE('Medidas Clientes'[Clientes], [Potencial Cidade])
19. Métodos Avançados em Python
- Clusterização K-Means:
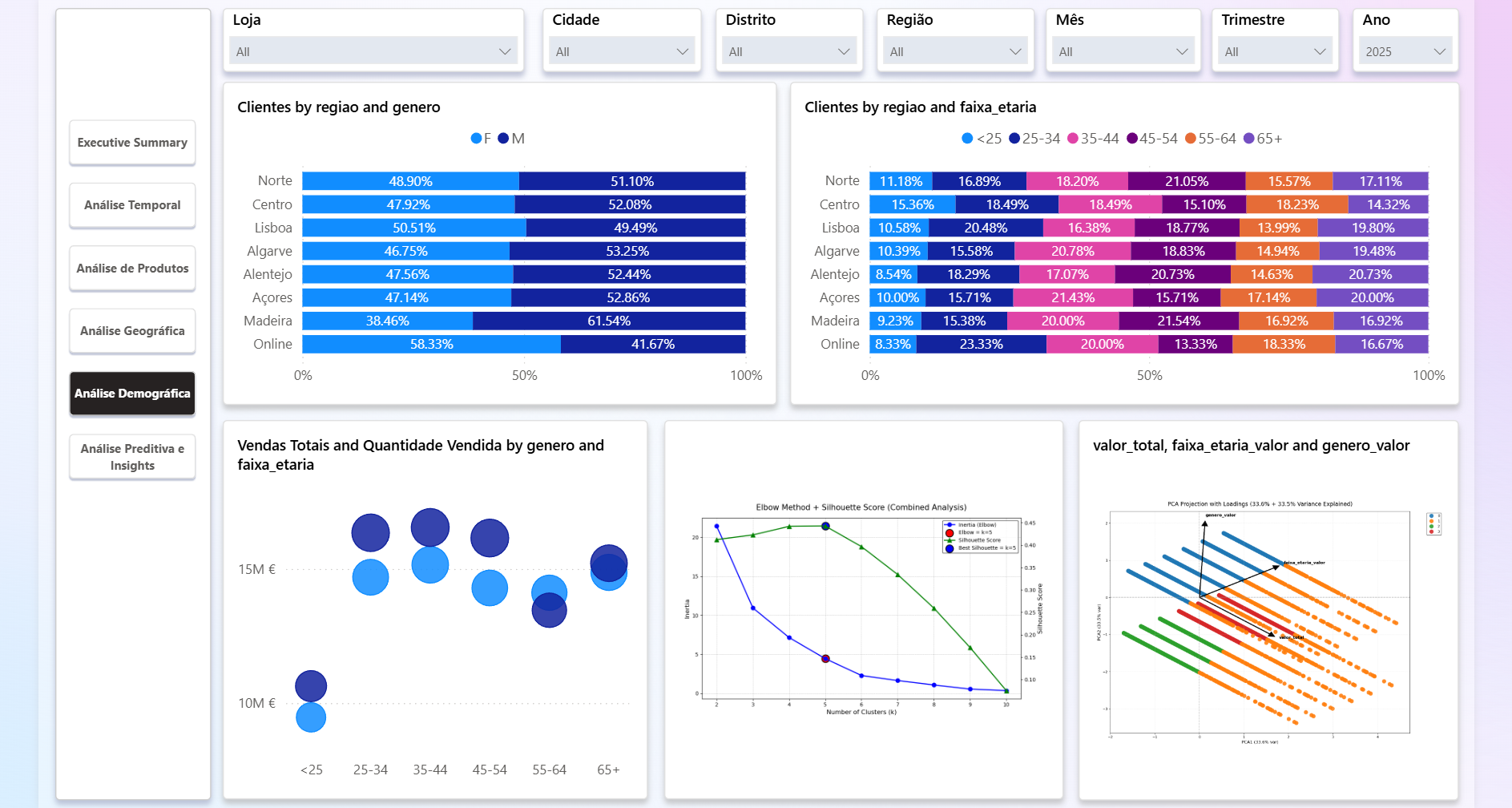
powerbi/elbow_method.py(método do cotovelo) epowerbi/silhouete_score.py(silhouette) para escolherkcom featuresVendas Totais,faixa_etaria_valor,genero_valor(usar dataset do visual Python).
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
# Estilo para fundo claro
plt.style.use('default')
plt.rcParams['figure.facecolor'] = 'white'
plt.rcParams['axes.facecolor'] = 'white'
plt.rcParams['axes.edgecolor'] = 'black'
plt.rcParams['axes.labelcolor'] = 'black'
plt.rcParams['xtick.color'] = 'black'
plt.rcParams['ytick.color'] = 'black'
plt.rcParams['text.color'] = 'black'
plt.rcParams['legend.edgecolor'] = 'black'
plt.rcParams['legend.labelcolor'] = 'black'
plt.rcParams['axes.titlepad'] = 15
# 1) Carregar dataset do Power BI
df = dataset.copy()
df = df.dropna(subset=['Vendas Totais', 'faixa_etaria_valor', 'genero_valor'])
# 2) Seleção de features
X = df[['Vendas Totais', 'faixa_etaria_valor', 'genero_valor']].values
# 3) Normalizar
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 4) Calcular métricas para k = 2..10
k_values = range(2, 11)
inertias = []
silhouette_scores = []
for k in k_values:
kmeans = KMeans(n_clusters=k, init='k-means++', n_init=10, random_state=42)
labels = kmeans.fit_predict(X_scaled)
inertias.append(kmeans.inertia_)
silhouette_scores.append(silhouette_score(X_scaled, labels))
# 5) Ponto de cotovelo
x1, y1 = k_values[0], inertias[0]
x2, y2 = k_values[-1], inertias[-1]
distances = []
for i, k in enumerate(k_values):
x0, y0 = k, inertias[i]
num = abs((y2 - y1)*x0 - (x2 - x1)*y0 + x2*y1 - y2*x1)
den = np.sqrt((y2 - y1)**2 + (x2 - x1)**2)
distances.append(num / den)
elbow_k = k_values[np.argmax(distances)]
elbow_inertia = inertias[np.argmax(distances)]
# 6) Melhor silhouette
best_silhouette_k = k_values[np.argmax(silhouette_scores)]
best_silhouette_score = max(silhouette_scores)
# 7) Gráfico combinado
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.plot(k_values, inertias, 'bo-', linewidth=2, markersize=8, label='Inertia (Elbow)')
ax1.set_xlabel('Number of Clusters (k)', fontsize=12)
ax1.set_ylabel('Inertia', fontsize=12, color='black')
ax1.tick_params(axis='y', labelcolor='black')
ax1.scatter(elbow_k, elbow_inertia, s=220, c='red', edgecolor='black', linewidth=1.5, label=f'Elbow = k={elbow_k}')
ax1.grid(True, linestyle='--', linewidth=0.6, alpha=0.5, color='gray')
ax2 = ax1.twinx()
ax2.plot(k_values, silhouette_scores, 'g^-', linewidth=2, markersize=9, label='Silhouette Score')
ax2.set_ylabel('Silhouette Score', fontsize=12, color='black')
ax2.tick_params(axis='y', labelcolor='black')
ax2.scatter(best_silhouette_k, best_silhouette_score, s=220, c='blue', edgecolor='black', linewidth=1.5, label=f'Best Silhouette = k={best_silhouette_k}')
plt.title('Elbow Method + Silhouette Score (Combined Analysis)', fontsize=15, color='black')
lns1, labs1 = ax1.get_legend_handles_labels()
lns2, labs2 = ax2.get_legend_handles_labels()
plt.legend(lns1 + lns2, labs1 + labs2, facecolor='white', edgecolor='black', labelcolor='black', loc='best')
plt.tight_layout()
plt.savefig("combined_elbow_silhouette_white.png", dpi=300, bbox_inches='tight')
plt.show()
- PCA:
powerbi/pca.pygera biplot com loadings, valida variância explicada e destaca grupos (cores/estilos personalizáveis para fundo escuro).
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
plt.rcParams['axes.facecolor'] = 'white'
plt.rcParams['axes.edgecolor'] = 'black'
plt.rcParams['axes.labelcolor'] = 'black'
plt.rcParams['xtick.color'] = 'black'
plt.rcParams['ytick.color'] = 'black'
plt.rcParams['text.color'] = 'black'
plt.rcParams['legend.edgecolor'] = 'black'
plt.rcParams['legend.labelcolor'] = 'black'
plt.rcParams['axes.titlepad'] = 15
cluster_palette = ["#1f77b4", "#ff7f0e", "#2ca02c", "#d62728", "#9467bd", "#8c564b"]
df = dataset.copy()
df = df[['valor_total', 'faixa_etaria_valor', 'genero_valor']].dropna()
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df)
BEST_K = 4
kmeans = KMeans(n_clusters=BEST_K, init='k-means++', n_init=10, random_state=42)
df['cluster'] = kmeans.fit_predict(X_scaled)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
loadings = pca.components_.T * np.sqrt(pca.explained_variance_)
pca_df = pd.DataFrame(X_pca, columns=['PCA1', 'PCA2'])
pca_df['cluster'] = df['cluster']
feature_names = ['valor_total', 'faixa_etaria_valor', 'genero_valor']
fig, ax = plt.subplots(figsize=(14, 10))
sns.scatterplot(
data=pca_df,
x='PCA1', y='PCA2',
hue='cluster',
palette=cluster_palette,
s=140, alpha=0.9,
edgecolor="none",
ax=ax
)
arrow_scale = 2.3
for i, feature in enumerate(feature_names):
ax.arrow(0, 0, loadings[i, 0] * arrow_scale, loadings[i, 1] * arrow_scale, head_width=0.12, head_length=0.12, fc='black', ec='black', lw=2.5)
ax.text(loadings[i, 0] * (arrow_scale + 0.3), loadings[i, 1] * (arrow_scale + 0.3), feature, fontsize=12, color='black', weight='bold')
var1 = pca.explained_variance_ratio_[0] * 100
var2 = pca.explained_variance_ratio_[1] * 100
ax.set_title(f"PCA Projection with Loadings ({var1:.1f}% + {var2:.1f}% Variance Explained)", fontsize=16, color='black')
ax.set_xlabel(f"PCA1 ({var1:.1f}% var)", fontsize=12)
ax.set_ylabel(f"PCA2 ({var2:.1f}% var)", fontsize=12)
ax.axhline(0, color='grey', linestyle='--', alpha=0.6)
ax.axvline(0, color='grey', linestyle='--', alpha=0.6)
ax.grid(True, linestyle='--', alpha=0.35, color='lightgrey')
legend = plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', frameon=True)
legend.get_frame().set_facecolor('white')
legend.get_frame().set_edgecolor('black')
plt.tight_layout()
plt.show()
- Forecasting (Prophet):
powerbi/prophet.pyagrega vendas diárias, remove outliers (p95), treina Prophet e produz forecast + intervalos; inclui análise de tendência/sazonalidade.
from prophet import Prophet
import pandas as pd
import matplotlib.pyplot as plt
df = dataset.rename(columns={'data': 'ds', 'valor_total': 'y'})
df['ds'] = pd.to_datetime(df['ds'])
df_daily = df.groupby('ds', as_index=False).sum()
df_daily = df_daily[df_daily['y'] < df_daily['y'].quantile(0.95)]
model = Prophet()
model.fit(df_daily)
future = model.make_future_dataframe(periods=120)
forecast = model.predict(future)
fig, ax = plt.subplots(figsize=(12, 7))
ax.scatter(df_daily['ds'], df_daily['y'], label="Historical Data", color='blue', alpha=0.6)
ax.plot(forecast['ds'], forecast['yhat'], label="Forecast", color='red', linewidth=2)
ax.fill_between(forecast['ds'], forecast['yhat_lower'], forecast['yhat_upper'], color='red', alpha=0.2, label="Confidence Interval")
ax.grid(True, linestyle='--', alpha=0.5)
ax.set_title("Prophet Forecast", fontsize=14)
ax.set_xlabel("Date")
ax.set_ylabel("Sales")
ax.legend()
plt.tight_layout()
plt.show()
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as plt
df = dataset.rename(columns={'data': 'ds', 'valor_total': 'y'})
df['ds'] = pd.to_datetime(df['ds'])
df = df[df['y'] < df['y'].quantile(0.95)]
model = Prophet()
model.fit(df)
future = model.make_future_dataframe(periods=90)
forecast = model.predict(future)
fig = model.plot(forecast)
plt.title("Actual Sales and Forecasted Sales (90 Days)")
plt.xlabel("Date")
plt.ylabel("Sales Units")
fig2 = model.plot_components(forecast)
plt.show()
- Cross Selling (M):
powerbi/Cross Selling.mdcria tabela de pares de produtos por transação e contanum_vendas_combinadaspara matrizes de calor.
Purchased Both Products (Cell) =
VAR ProdutoLinha = SELECTEDVALUE('dw DIM_PRODUTO'[nome])
VAR ProdutoColuna = SELECTEDVALUE('Comparaçao Produtos'[nome])
VAR TransacoesLinha =
CALCULATETABLE(
VALUES('dw FACT_VENDAS'[transacao_id]),
'dw FACT_VENDAS',
'dw DIM_PRODUTO'[nome] = ProdutoLinha
)
VAR TransacoesColuna =
CALCULATETABLE(
VALUES('dw FACT_VENDAS'[transacao_id]),
TREATAS({ProdutoColuna}, 'dw DIM_PRODUTO'[nome])
)
RETURN
IF(
HASONEVALUE('dw DIM_PRODUTO'[nome]) &&
HASONEVALUE('Comparaçao Produtos'[nome]) &&
ProdutoLinha <> ProdutoColuna,
COUNTROWS(INTERSECT(TransacoesLinha, TransacoesColuna))
)
Purchased Both Products =
VAR Result =
IF(
ISINSCOPE('dw DIM_PRODUTO'[nome]) &&
ISINSCOPE('Comparaçao Produtos'[nome]),
[Purchased Both Products (Cell)],
SUMX(
SUMMARIZECOLUMNS(
'dw DIM_PRODUTO'[nome],
'Comparaçao Produtos'[nome]
),
[Purchased Both Products (Cell)]
)
)
RETURN Result
- Cálculos visuais: Pareto em
powerbi/Visual_calculations.md; tabelas auxiliares para slicers empowerbi/tabelas_auxiliares.md.
Percent of grand total = DIVIDE([Vendas Totais], COLLAPSEALL([Vendas Totais], ROWS))
Running sum = RUNNINGSUM([Percent of grand total],ORDERBY([Vendas Totais],DESC))
Greenline = IF([Pareto]<=.8,[Pareto],BLANK())
Redline = IF([Pareto]>.8,[Pareto],BLANK())
20. Licença
- Licença MIT (ver
LICENSE).